
Machine Learning is sometimes wrong — how you deal with that is EVERYTHING
Imagine if you were using a calculator to do some just fantastic calculations like π^π , !2, or the old standard 2+2, and every once-in-a-while, the answer would came back wrong. Better yet, you’ve implemented a microservice in your stack that occasionally just returns {[“No”]}.
This is what working with machine learning can feel like sometimes. You’re sitting there feeding it pictures of cats, and it is returning the label “cat” consistently until suddenly “guacamole” comes back.
Why?!
Because.
Is this real life?
Yes, this is real life. Machine learning models, especially ones using neural networks, work in mysterious ways. We train them with lots of examples of cats, and it builds itself in a way that understands what cats look like. It is not too dissimilar to how the human brain works, but a much much much much much¹⁰ simpler version. Even so, we don’t really tell the neural networks what to do, they figure it out on their own based on your training data. There are hidden layers in deep neural networks that connect themselves in ways that make sense for your training data but have no input from us humans. We don’t tell it “this is what an eye looks like”, it just figure it out on its own.
What could possibly go wrong?

Machine learning is not about a definitive answer (yet), it is about statistics. Kind of like casinos, and in this case, you’re the house and you design systems that work in your favor.
So I shouldn’t use it then?
Fortunately, I have a definitive answer for this one; yes, you should use it! Statistics are great, people use them all the time to solve problems and complete tasks. And you should too. In truth, machine learning is saving a lot of people time and money, and is accelerating businesses all over the place. One thing they’ve all got in common is that they’ve built their user experience, workflows, processes, etc., around the fact that sometimes the models are wrong.
Perhaps, instead of doing an amazing job of explaining exactly what I mean, I’ll just give you some examples.
Example 1
Detecting nudity in video.
Video is tricky when it comes to image recognition, because what you’re dealing with is a series of frames, and as you can see from this article, sometimes something about an image just throws an image recognition model way off. See below, an example of an image recognition model correctly identifying a cat when the photo is tilted one way, but thinking it is guacamole when the photo is slightly altered.
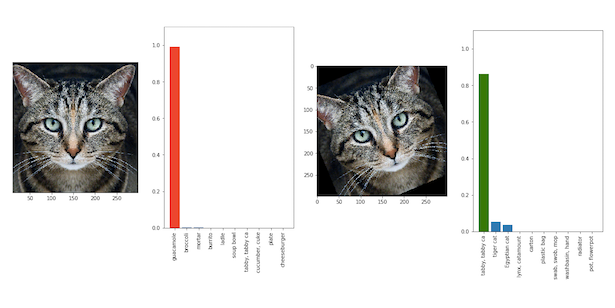
{kind=link}
If you build a workflow or system around needing every frame to have 100% accurate image recognition results, then you might run into trouble. However, if you think about the problem (I’m trying to send my phone an alert every time some guacamole ????s on my door mat), you may find that what you’re trying to solve doesn’t require frame-accurate results.
Let’s consider content moderation/nudity in video. If I’ve got a website that allows users to submit content in video, I might want to check it for nudity first. And since I get hundreds of uploads per day, I don’t really have the time to check it myself. So I turn to machine learning.
Even the machine learning models for detecting inappropriate content coming out of the massive tech giants just do okay on this problem. If I’m looking for specific incidents within a video of nudity, I’ll probably waste a lot of time hunting around looking at false positives.
BUT, what if I focused on saving myself time overall, and thought about the problem holistically?
“I don’t know, why don’t you tell me?”, you say in an incredibly irritated voice.
Okay I will. Consider your model is returning true or false for a lot of frames, and with those results comes a confidence score of some kind. Imagine if you crunched the entire video’s results to create a heat map of severity, so in a glance, you could tell just how likely 1, 200, 2000 or more videos had nudity in it that you needed to review.
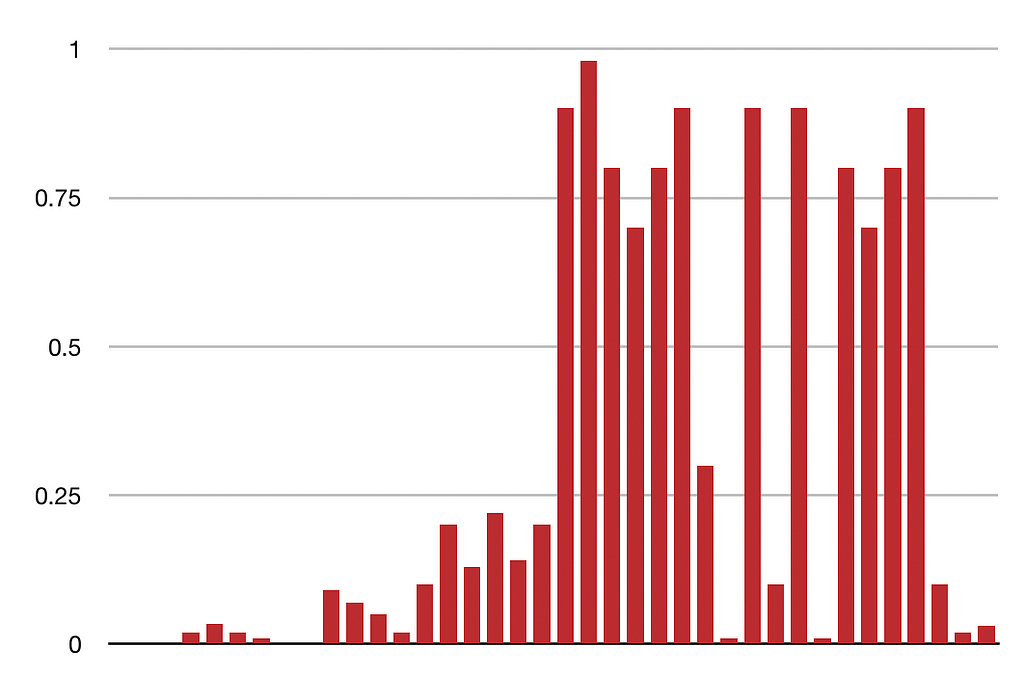
Instead of reviewing every video’s flag at every point where it thinks there might be nudity as a true or false, I can just discard everything that falls below a certain threshold, and focus on the videos that really needs it. But I can also not get caught up by the one or two times the model got it wrong, and look at the broader picture… so to speak.
I should also add that if it is wrong, it might be good to have a button that feeds that now-labeled frame back into your model for some additional training.
Example 2
What is this video about?
If you’re sensing a theme about video here, then you’re wrong. The theme is about machine learning and image recognition. PAY ATTENTION. But video keeps cropping up because it presents a chance for us to consider image recognition at scale.
Let’s consider some of the image recognition capabilities out there that are pre-trained. These systems, given an image, will tell you if it is a picture of a cat, like the example above. But it will give you other tags as well; feline, tabby, animal, mammal, photo, etc.
Imagine if you did that for every second of footage of a baseball game. You’d be quickly overwhelmed with irrelevant information. A less than ideal use of this information would be trying to pinpoint every spot in a video where there are cats. A better use case would be to look at your 8 billion hours of video content more holistically.
Let’s consider the following word cloud.
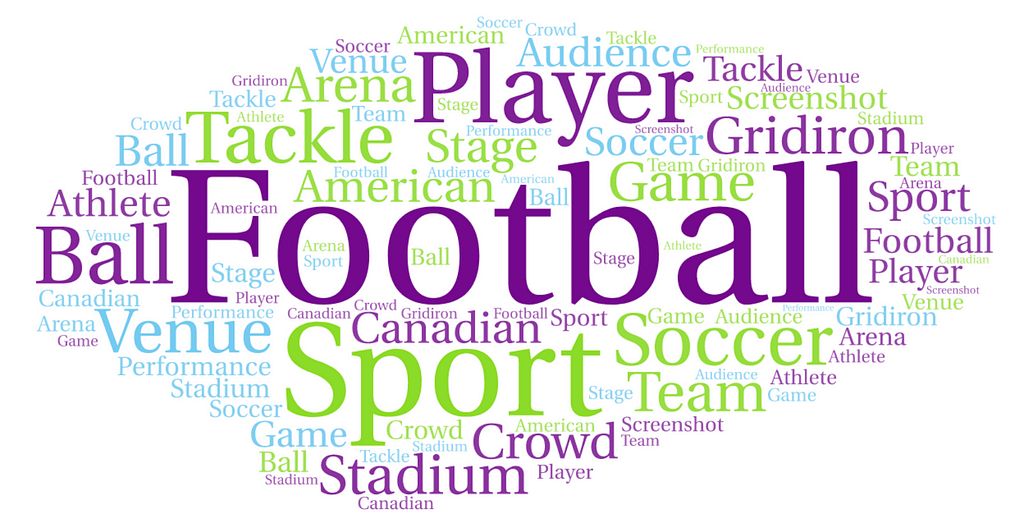
What is this video about? We simply took the total list of tags an image recognition system came back with with their frequency (how many times the tag came up in the video), and pumped into a standard, free online word cloud generator and got this beautiful blob.
The image recognition might not have gotten every frame correct, but I’m still getting a lot of value in this scenario where I don’t know what video content I have.
Example 3
Detecting faces

I love how Apple Photos does this. They show you a group of faces and then ask you to tell it who that person is. It trains a model, then applies it to all new photos. Sometimes, the confidence is low, so it periodically asks you “is this person Human McHuman?” (I’m not great at coming up with fictional names).
What I love about this process is that it involves you as the human to improve the model somewhat seamlessly, gives you a sense of satisfaction about teaching it things, and encourages you to interact with the product more than you normally would.
It is, in my opinion, one of the best implementations of visual machine learning I know of. It is simple, effective, and fun. Good job Apple, you’re good at computers!
Conclusion
What have we learned? Probably not much — I’m not a very good writer.
But I am hoping that we can start to think about the best ways to implement a system that is sometimes wrong, and even use that oddness to our advantage as product/business people (like encouraging people to interact with a product to make it better by investing time teaching a model).
Ok… yeah, you get it. BYE!
https://medium.com/media/b85dfbb5286d8a25cf2e754b9462cf45/href![]()
Machine Learning is sometimes wrong — how you deal with that is EVERYTHING was originally published in Prototypr on Medium, where people are continuing the conversation by highlighting and responding to this story.